
因為前兩年擔任梅竹黑客松籌備幹部的關係,所以很自然的就跟大家講好說一定要再回來參加比賽,除了累積實務經驗,也順便看看下一屆的學弟妹籌備的如何。
作品介紹
Text Mode
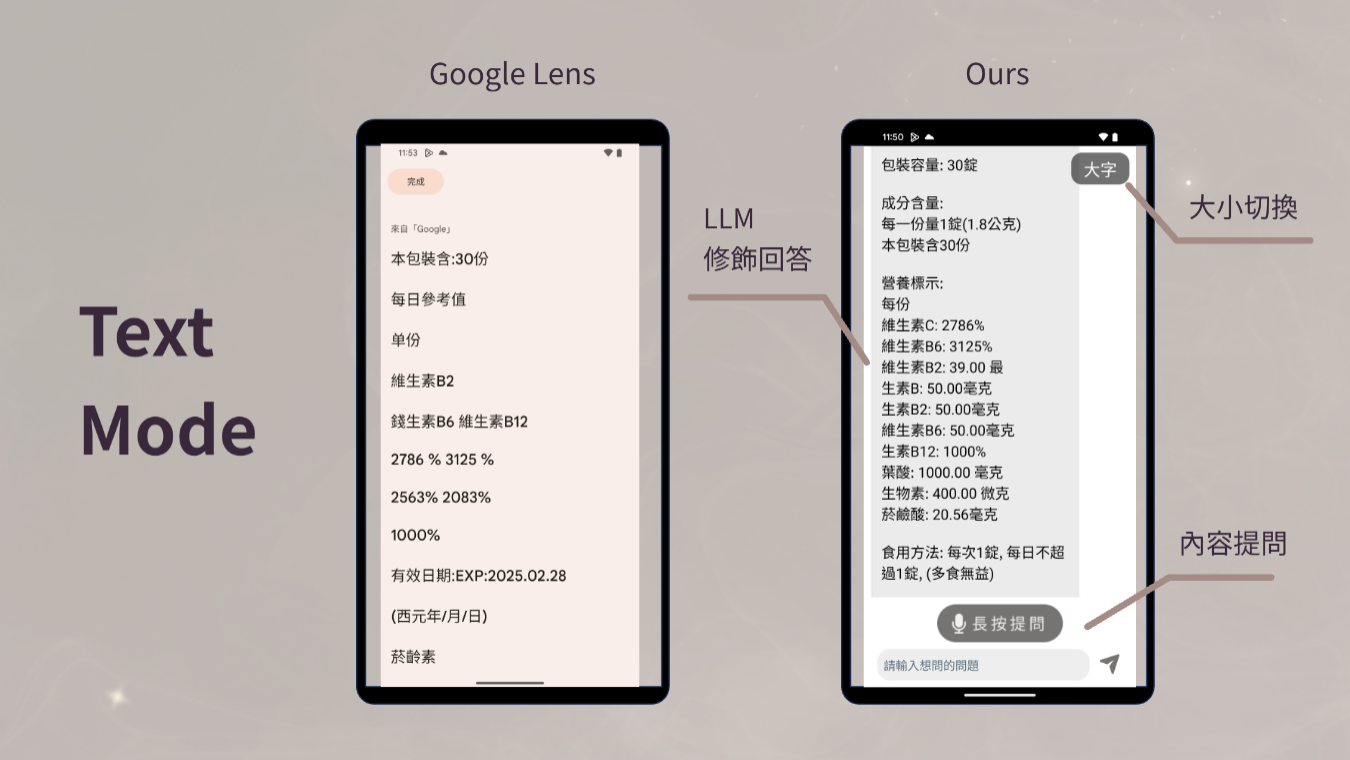
這個功能主要是為了視力不好的人設計的,家裡有些長輩看一些小字的時候常常會看不清楚,例如說標籤、說明書等等,因此我們設計了文字放大鏡來解決這個問題。 使用者可以將當下他要閱讀的文本拍攝下來,利用圖像轉文字的 API 我們可以分離出文字,再來結合大型語言模型重新整合資訊並排版再呈現給使用者,同時使用者可以根據文本的內容作提問,例如說他可以問:這瓶飲料保存期限為何?我們的 App 整合完資訊後就會回答使用者,方便他們擷取自己需要的資訊。
Object Mode

這個功能主要是為了讓視障者有獨立生活的能力,我們的目標是視障者在找尋物品的時候,透過影像辨識,可以根據 APP 給的提示就走到物品真正的位置。使用者首先會告訴 APP 說他想要找尋甚麼樣的物品,再來根據影像辨識的結果,APP 匯提示使用者方位,例如:向左走、向右走等等,最終就可以找到目標物品。
技術架構
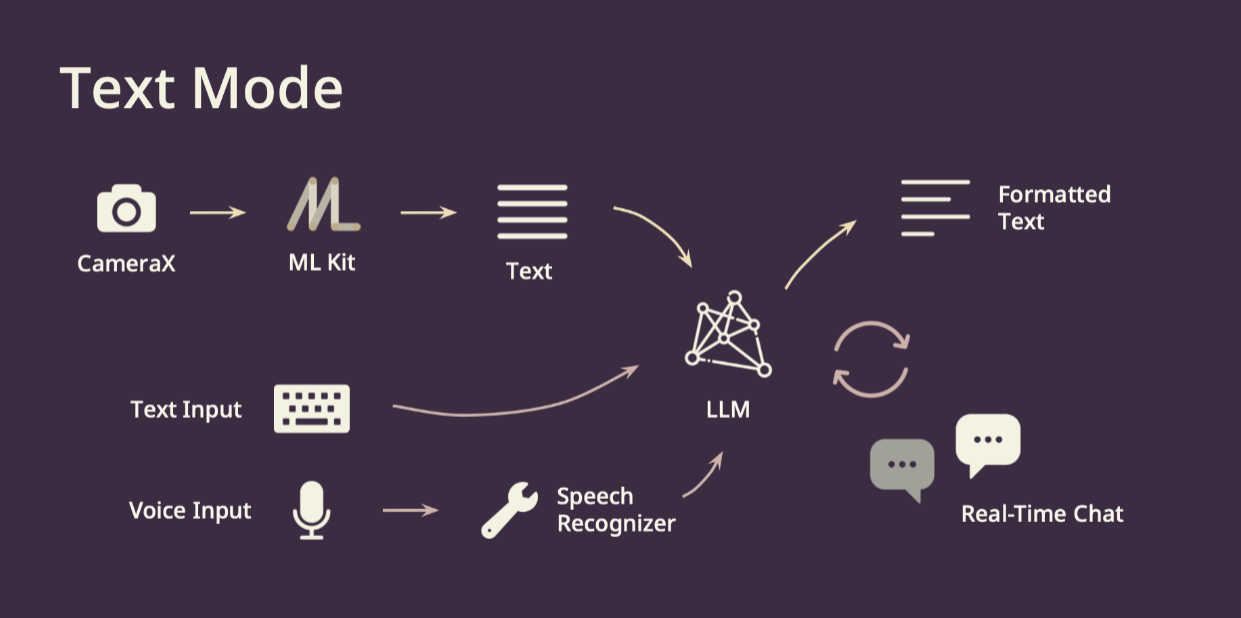
Text Mode 的部分我們利用 ML Kit 將圖片轉成文字,再來利用大型語言模型,給定設計過的 Prompt 讓其整合我們傳過去的資料,並讓他可以回答使用者的問題。
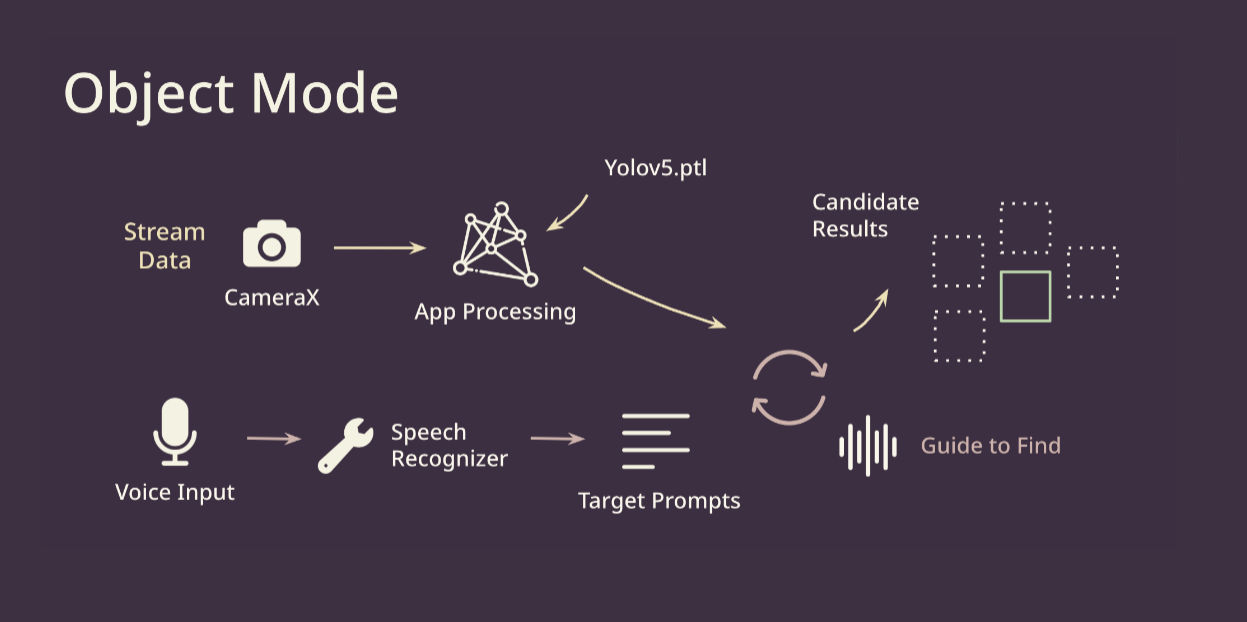
Object Mode 我們利用 lightweight Yolov5 來處理影像判斷物體位置,我們可以直接讓輕量的模型跑在手機上,這樣可以實現離線處理的功能以及提高它的效能。再來我們使用客製化的 Dataset 來 fine tune 我們的 model,讓他可以更精準的判斷目標物體的位置。
參賽心得
我們很幸運的抽到 Google 組,這次題目是透過 Android Accessibility API 發想並設計好的功能用戶體驗,這個題目對我們來說是非常困難的,「無障礙 APP」這個主題能發揮的空間太有限了,我們前前後後想了非常多主題,但是永遠繞不過兩個問題,一是已經有競品出現,二是技術層面過於簡單不利於比賽,這種比賽最困難的地方我認為反而不是實作,反而是要想出一個既有技術層面的展現,又有創意並且正確解決到使用者痛點的專案,才可以真正從比賽中脫穎而出。
花了好久的時間才決定題目,等到開始做專案應該已經剩下 5 天了,最可怕的是全組 5 個人沒有一個人碰過 Android App,算是一個非常大的挑戰。除了多學了一項技能,這次的比賽真的有黑客松的感覺,我們需要在極短的時間內完成一個專案,勢必得要在品質跟完成度之間做取捨,我們整組真的拚盡全力在準備這次的比賽,對我來說是一次很棒的體驗。
可能是因為自己辦過的關係所以非常清楚會場中幾乎所有細節,看到下一屆的幹部在現場壓力很大其實也是滿心疼的,有些參賽者可能會因為籌備團隊的一些細節沒有處理好貨是沒有規劃周全就會對籌備方惡言相向,我自己是覺得大家可以好好給建議,這樣可以將這些建議傳承下去讓這個活動越來越好,身為籌辦方一定不會想要隨隨便便處理這個活動,大家一定是盡全力在做事,那不管做任何事情都一定會有考慮不周全的情況,既然如此一些激烈的言論我是覺得就沒有必要了,籌辦了一年大家都非常辛苦,多一點包容多幫忙給一點建議,這個世界才會越來越好。